
ToC
Open ToC
🦆🦆🪿 Duck, duck, goose
Today is an exciting time in data. New tools have the opportunity to revolutionize not only how data engineers work, but how companies architect data platforms.
I mostly agree with Tristan Handy’s characterization of the MDS through 2020: there was a period of explosive growth in the mid- to late-2010’s, followed by a stall (and COVID). I firmly believe that we’re amidst a second renaissance in data tooling.
DuckDB is a great example of a new tool that has tremendous promise— in its intended use as an OLAP DBMS, but also for all sorts of tangential cases. I’ll discuss those a bit today, but first, some background: a few weeks ago I saw Daniel Beech’s post: DuckDB vs. Polars, which led me to experiment with DuckDB the same way he did. Since then, I’ve been fiddling with the tool and chatting with others— I’ve even given a few lightning talks on what I’ve found.
Of course, I’d be remiss if I didn’t share my thoughts completely— so that’s what I’ll do!
🌎 So, what on earth is DuckDB?
Let’s dig in! According to the folks at DuckDB:
DuckDB is an in-process SQL OLAP database management system
🤔 That doesn’t clear much up. Let’s break it down.
DuckDB is an in-process ..
Ok, so it runs in-process— that means DuckDB shares memory with your host language, but it can process larger than RAM datasets and persist to disk. Here’s a solid write-up of what it means to be in-process.
💡 NOTE: V1 of this post incorrectly stated DuckDB was an in-memory database.Thanks to Alex Monahan for the correction. In-memory DBs are something entirely different (almost precisely the opposite of in-process DBs 🤣). A topic for a future post!
.. SQL OLAP ..
Technically redundant, but Online Analytical Processing is more-or-less a column-oriented database. Traditional databases (Postgres, MySQL) are row-oriented, which optimizes for fast reads/writes. Column-oriented DBs are optimized for analytics. We’ll discuss this a bit more later.
.. database management system ..
So not only a database but a system for creating and managing databases. Ah! Much better! But, how does it work?
⚙️ How it works
DuckDB utilizes a vectorized query engine. That’s a fancy way of saying operations are columnar. If you’re a data science ninja 🥷, you might be familiar with the complexities of vectorized dataframe ops (they’re a nightmare!).
Being a vectorized engine just means that large batches of values (vectors) are processed in a single operation. Vectorized execution leads to better performance in analytical calculations, which are often performed over all values in a particular column, e.g. an aggregation like SUM, MAX or window, such as ROW_NUMBER.

While technically not new, there’s a pretty big movement in the open source community right now: PyArrow, Polars, Pandas 2.0, and DuckDB all tools built on in-process, vectorized operations. Usually, when many things point in the same direction, it’s wise to take note! 📝
While the features of DuckDB are not new— we’ve had OLAP DBMS for years: the real innovation behind DuckDB is its simplicity and distribution (free & open-source).
🫵 Why you should care
Most databases are complicated. Today, we have managed solutions (Amazon RDS, BigQuery, etc), they can be expensive, especially managed OLAP solutions (as I’m sure many Snowflake customers are aware).
Not only is configuration a headache but truly understanding how pricing works can be a nightmare. This is a problem for data teams, but also those seeking to learn and play— it creates barriers to new and potential data engineers.
Here’s an example: say I want to install Postgres to learn about databases, as I’m sure many have done in their data journeys. Navigating to Chapter 17 (!) of the Postgres docs, we find Installation from Source Code, which sounds both intimidating and not particularly fun. It’s telling that section 17.1 is titled “Short Version,” which already makes me nervous about what lies ahead. This will be a daunting quest. ⚔️
Similarly, if we want to understand how modern databases work, we might seek out whitepapers or technical documents, for example:
And just like that, we’re neck deep in academic papers reading about “cloud-powered massively parallel query services.” 😬
By contrast, from the DuckDB docs:
pip install duckdbHm… That’s a bit more approachable. Not only that but there’s native support for reading from semi-structured sources like parquet, CSV, etc.
SELECT * FROM read_parquet('input.parquet');
CREATE new_tbl AS SELECT * FROM read_parquet('input.parquet');Wow! So basically, we can go from zero ➡️ in-process, vectorized databases with:
- A python installation
- Three lines of code
- Some sample data
This is huge 🤯.
🌄 Possibilities
This is the part where I deliver some off-the-wall theories about how this will be awesome, game-changing, etc.

Replacement for managed OLAP systems
Redshift, BigQuery, and Snowflake are all excellent tools. They’ve revolutionized data processing and storage, but they’re expensive and require expertise to maintain. I think these solutions will always have a place on some teams, but others might opt for DuckDB— especially those who are resource constrained. As the tool develops, I could see it emerging as a true competitor to managed OLAP services.
Many claim the death of the centralized data warehouse. While data technology might be trending in that direction, this is far from reality for the majority of data teams. However, DuckDB could be one step closer to that end.
Database representation of a staging layer
This is a bit more abstract, but DuckDB could serve as an upstream transformation layer, for those that aren’t ready to give up their warehouse.
Hear me out— imagine you have a data-lake situation. While SQL has its pitfalls, it is an excellent language for transforming data. With DuckDB, you could pull in semi-structured data and perform light SQL transformations without leaving the lake. Using a tool like dbt (or SQLMesh), you then have a versioned, transformation-as-code system!
With a connector tool, you could write that transformed data to your final destination, whether that’s another DuckDB-DB or something like Postgres, Redshift, etc. This brings the benefit of databases and structured data up a layer, from analysts to data engineers. I could imagine DuckDB fitting into the final stages of a medallion architecture.
Maybe that’s a stretch, but I think it has potential. 🤔

An awesome opportunity for tutorials and learning
OK, so the earlier solutions are a bit out-there, but this one is tangible and immediate. Most OLAP systems are hard to configure and difficult to learn. Most of the time, it takes hours of fiddling just to be able to write some SQL. Furthermore, it’s ambiguous how much free cloud credits are worth, and I’m frequently worried that I’ll be charged at some point for fiddling around in BigQuery. 😅
With DuckDB, we have a free, open source way to set up training and sandbox environments. I think a SQL tutorial site built on fabricated data in DuckDB would be awesome.
As a former analyst, the best way to learn SQL is by answering questions and playing around with a database. Though things are much further along than they once were (I remember leafing through Learning SQL back in the day), an interactive console built on DuckDB could be invaluable for analytics training and a staple in data engineering portfolio projects.
Ben Rogojan has an awesome post highlighting a few of these, but he forgot about DuckDB! Why spend hours configuring a source that you won’t be able to maintain when you could simply drop DuckDB in a container?

… but now for what I really want to talk about— simplifying a common data engineering task with DuckDB.
1️⃣ One-line partitioned parquet
This is a pretty neat trick and something Daniel Beech first brought to light. Here, we’ll take his demo one step further.
That’s right folks, you made it this far— you’re getting the good stuff. All three of you. 😂
A common data-eng problem is taking some input (usually a CSV or JSON), partitioning it, and storing it in an appropriate format in cloud storage (parquet in s3).
This might lead you to write grizzly Airflow DAGs with hideous chunking logic:
def upload_df_to_parquet(df, prefix, chunk_size=250000, **parquet_wargs):
"""Writes pandas DataFrame to parquet format with PyArrow.
Args:
df: DataFrame
prefix: s3 directory where parquet files are written to
chunk_size: number of rows stored in one chunk of parquet file. Defaults to 1000000.
"""
logger.info(f"Uploading df")
s3_hook = S3Hook(aws_conn_id=AWS_CONN)
for i in range(0, len(df), chunk_size):
slc = df.iloc[i : i + chunk_size]
chunk = int(i / chunk_size)
fname = os.path.join(prefix, f"part_{chunk:04d}.parquet")
logger.info(f"Uploading {fname}")
with BytesIO() as buffer:
slc.to_parquet(buffer, **parquet_wargs)
s3_hook.load_bytes(
bytes_data=buffer.getvalue(),
bucket_name=S3_BUCKET,
key=fname,
replace=True,
)That’s… less than ideal, hard to edit, and easy to break. There has to be a better way— and there is!
For our example, we’ll use the FDIC’s failed bank list dataset, since it’s small, somewhat manageable, and timely.
First, let’s connect DuckDB and define our urls:
import duckdb
import pandas as pd
import os
from dotenv import load_dotenv
conn = duckdb.connect()
# source
url = 'https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list/banklist.csv'
# target
s3 = 's3://ahhh-buck-it/spectrum/us_banks/'I had trouble reading this URL directly using DuckDB, I suspect due to the Windows encoding (wtf FDIC 😑), so we’ll use pandas. Hopefully, DuckDB will support reading these CSVs directly one day.
# do pandas stuff
bank_df = pd.read_csv(url, encoding='windows-1251')
bank_df.columns = [c.strip() for c in bank_df.columns]I also cleaned up the columns a bit— there were some trailing spaces hanging around. The FDIC data team could benefit from a data-eng bootcamp!
sample_cols = [
'Bank Name',
'City',
'State',
'Closing Date'
]
bank_df[sample_cols].head()| Bank Name | City | State | Closing Date |
|---|---|---|---|
| First Republic Bank | San Francisco | CA | 1-May-23 |
| Signature Bank | New York | NY | 12-Mar-23 |
| Silicon Valley Bank | Santa Clara | CA | 10-Mar-23 |
| Almena State Bank | Almena | KS | 23-Oct-20 |
| First City Bank of Florida | Fort Walton Beach | FL | 16-Oct-20 |
Nice! A cleaned dataset. Now we have to configure a few variables:
# authorize
load_dotenv('🤫/.aws/credentials')
# for communicating with s3
conn.sql('LOAD httpfs;')
# config
conn.sql(
f"""
SET s3_region='us-east-2';
"""
)
conn.sql(
f"""
SET s3_access_key_id='{os.environ['aws_access_key_id']}';
SET s3_secret_access_key='{os.environ['aws_secret_access_key']}';
"""
)FINALLY, THE MOMENT WE’VE ALL BEEN WAITING FOR. We’re ready for some magic. 🦄
conn.sql(f"COPY bank_df TO '{s3}' (FORMAT PARQUET, PARTITION_BY (State), ALLOW_OVERWRITE 1);")and, that’s it. We’re done!
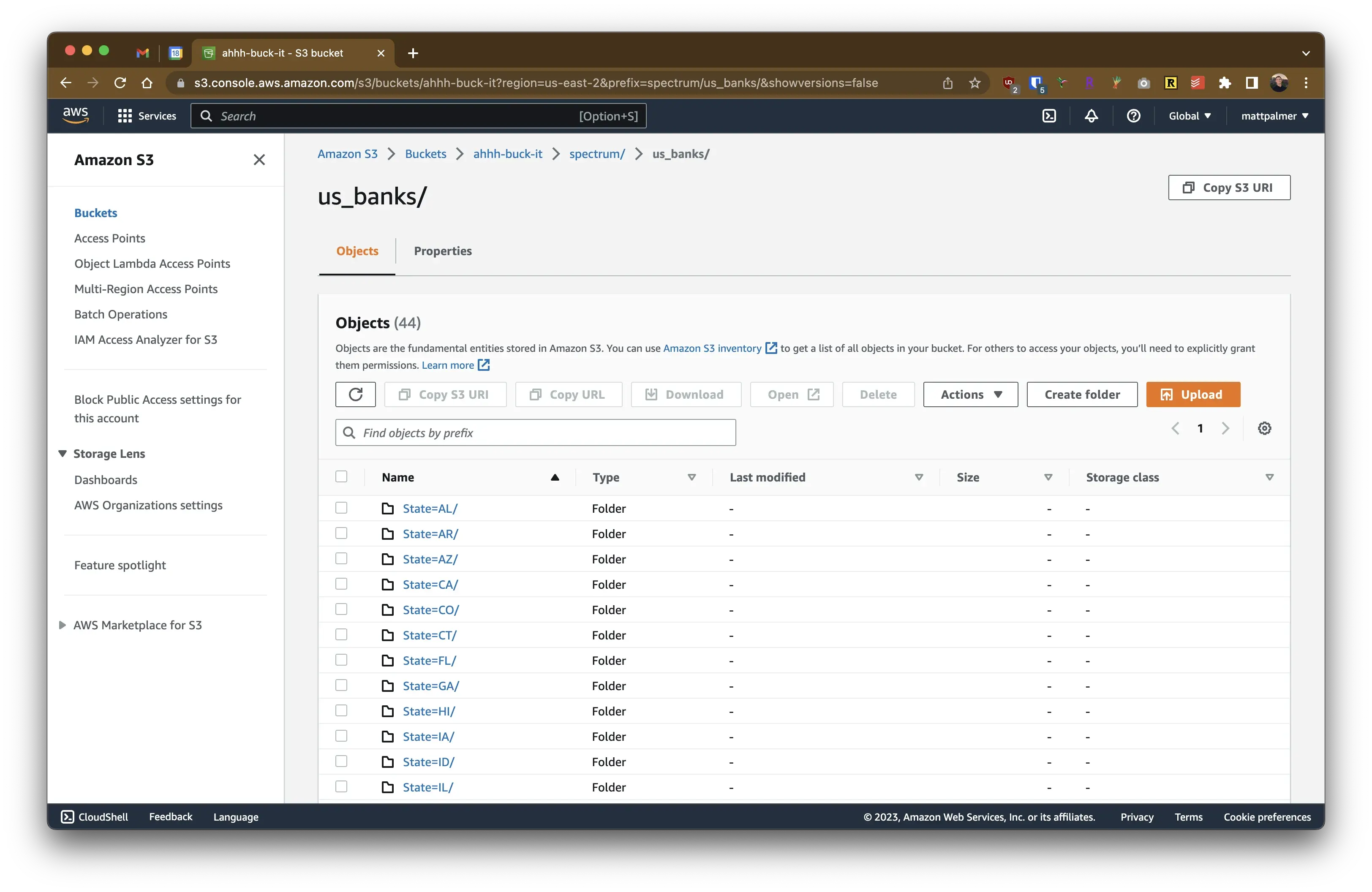
Perhaps I’m just easily impressed, but I think this is really neat. You could take it one step further and write a class/function that makes this a bit more robust and production-ready.
Again, I think the true value here is simplicity. Will this work at scale? Maybe not, but it’s incredibly easy to read and understand. Solving problems in the simplest way possible, in life and data engineering, is an art worth pursuing.
🎁 Wrap
One of my goals for this blog is to generate excitement for promising data engineering tech. DuckDB is a super accessible tool that has already generated a panoply of possibilities. If it’s not apparent, I’m exuberant about what’s to come, both from the open-source community and DuckDB labs.
If you have other use cases for DuckDB that I missed (or if you think I’m missing the mark), please reach out! I’d love to hear your thoughts. My About page has several ways to get in touch. 🙏