
ToC
Open ToC
🎞️ Intro
“Delta Lake” sounds more like a fun weekend hike than a part of the modern data stack. I’ve made my case before and I fully expect a data retreat to the Tetons in 2024 (yes, Databricks, I have room for a sponsorship).
Of course, Delta Lake is primarily an open-source lakehouse storage framework. It’s designed to enable a lakehouse architecture with compute engines like Spark, PrestoDB, Flink, Trino, and Hive. It has APIs for Scala, Java, Rust, Ruby, & Python.
Storage frameworks like Delta have played a major role in lakehouse architectures, but I’ve found the technology behind them unapproachable. What is it? Git for data? (no) How does it work? Why should I use this instead of Parquet? (this is Parquet!)
As always, we’ll break things down to the basics and give you a comprehensive picture of what Delta Lake is and how you can get started.
So…
🚤 What is Delta Lake?
While Delta is an open-source framework, it’s important to note that it also underpins the Databricks platform. That means Databricks uses Delta Lake for storing tables and other data. It should be no surprise they created the format & they’re subsequently responsible for most work on the library and its APIs.
Notably, as we’ll discuss in a follow-up post, Iceberg is a very similar format and powers some of Snowflake’s offerings… If you know about the ongoing feud between Databricks and Snowflake you can probably guess where this is headed. In typical fashion, we now have folks proclaiming ”Iceberg won this” or “Delta won that.” In reality, they’re storage formats. Extremely similar storage formats… but what does that mean?
If you peruse the Databricks/Delta docs, you’ll probably find something like this:
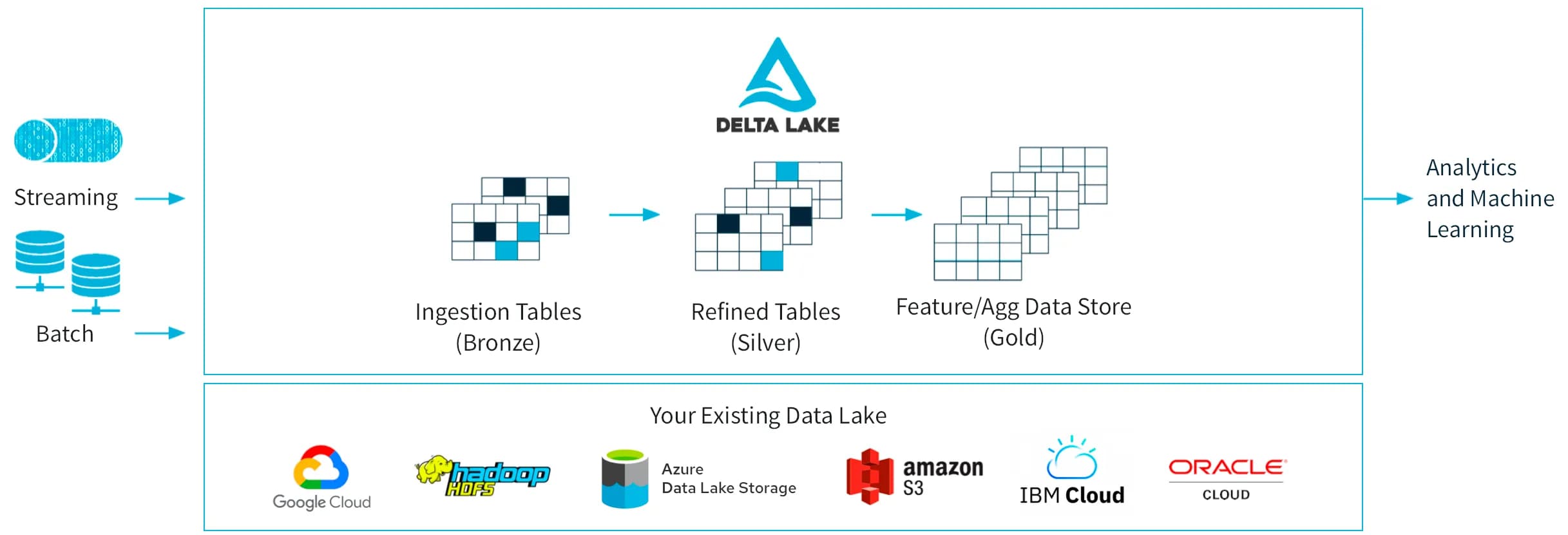
I don’t find this particularly helpful for understanding Delta Lake. For some reason, the majority of their docs describe a lakehouse framework with a medallion architecture, not the underlying technology. A lakehouse is a fancy buzzword, also created by Databricks, used to describe a solution combining data lakes and data warehouses, i.e. leveraging cloud storage with semi-structured data formats and traditional OLAP solutions.
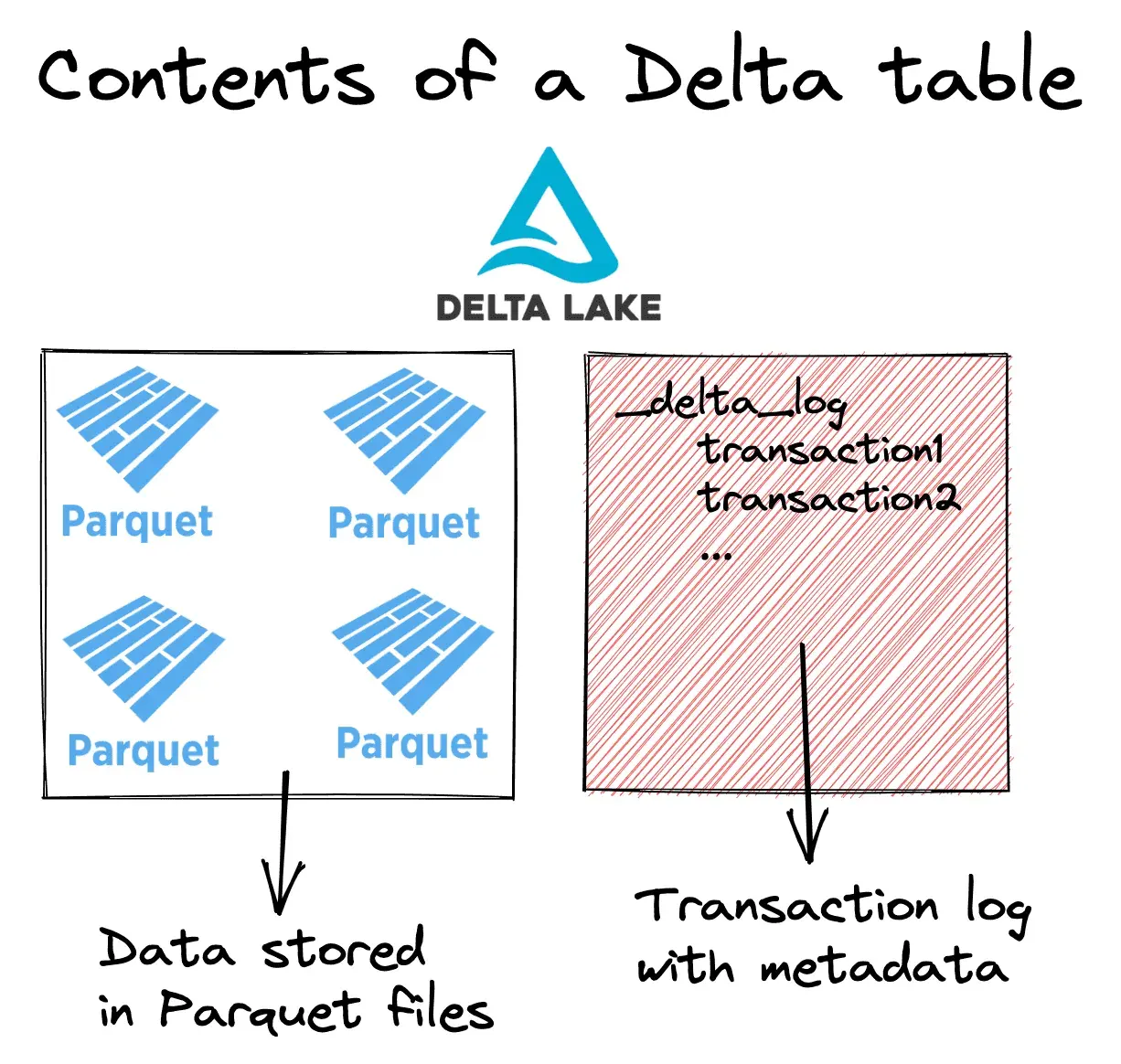
The very simple truth is that Delta files are just Parquet files with a metadata layer on top. That’s it. Not to understate the ingenuity and usefulness of Delta, but it’s a pretty simple concept.
Now, if you have a bit of background with these technologies, you might remark “Hey, so is Iceberg” or “Huh, that sounds like Hudi” and you’d be right. Those formats are pretty much the same thing. They even use very similar marketing materials.

All of these formats originated at companies that needed production-grade data lakes at scale, specifically those with a heavy reliance on Spark for processing. They’re designed to address shortcomings of Hive, primarily.
You might notice most features comprise reliability, quality, and disaster recovery. These companies needed to process massive amounts of data and be certain they could roll back changes, make simultaneous edits, and store reliable data: Hudi was started by Uber, Iceberg by Netflix, Delta by Databricks.
The key benefits of these formats are almost entirely obtained from those metadata layers— ACID guarantees, scalability, time travel (❗️), unified batch/streaming, DML ops, and audit histories, to name a few.
Now, this sounds like a whole lot, but remember this all comes from the metadata layer, so it can’t be too complicated (or can it?)
I’ll give a brief overview of key features, then dive into maybe the most important characteristic, the transaction log.
🔑 Key Features of Delta
ACID Guarantees
Ok, this term gets thrown around a lot without much explanation. Databricks has a nice writeup on these, but for posterity, ACID stands for:
- Atomicity: all transactions succeed or fail completely (no partial writes, for example).
- Consistency: How data is observed during simultaneous operations. Delta uses something called “optimistic concurrency control” to handle consistency— we’ll discuss this in a future post. For now, we’ll only note that it sounds nicer than pessimistic concurrency control.
- Isolation: simultaneous operations are handled without conflict. Again, this depends largely on optimistic concurrency control.
- Durability: committed changes are permanent. Delta simply relies on cloud object storage for this guarantee: “Because transactions either succeed or fail completely and the transaction log lives alongside data files in cloud object storage, tables on Databricks inherit the durability guarantees of the cloud object storage on which they’re stored.”
Time Travel

Easily the coolest sounding feature of Delta, time travel ⏰ allows us to query older snapshots of tables using stored metadata (up to 30 days, by default).
I think the most obvious application is disaster recovery, but as a former analyst, getting questions like “why did this number change,” or “why doesn’t this number equal this number” was an *ahem* unfortunate part of my job.
Being able to query tables at various states is huge for debugging purposes and triaging data errors, not just for analysts!
Time travel has many other uses as well:
- An improved snapshot: time travel can backfill missed snapshots (up to 30 days), unlike a
dbt snapshot. - Cumulative table design: this could be a useful way to build a cumulative table architecture that only requires a single source table.
- Audit purposes: isn’t compliance fun? Delta enables audit trails, for analysts/engineers and auditors alike.
The query syntax is exactly what you’d expect:
SELECT * FROM table_name TIMESTAMP AS OF timestamp_expressionThis works by using _delta_log files. Delta finds the snapshot closest to the requested timestamp then “replays” the recorded changes. We’ll give a demo of what these files look like later in this post!
A pretty important note from Delta:
The timestamp of each version N depends on the timestamp of the log file corresponding to the version N in Delta table log. Hence, time travel by timestamp can break if you copy the entire Delta table directory to a new location.
So don’t go moving Delta files around! 👀
Scalable Metadata
Ok, so I’m pretty skeptical of just how scalable Delta metadata is, but they claim:
Scalable metadata handling: Leverages Spark distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
So here’s my question: if you’re streaming petabyte-sized tables and capturing granular metadata on every change, I’d assume your ability to retain data drops pretty rapidly.
I don’t have experience with anything petabyte-sized (perhaps someone in the audience can chime in) so I’m curious what a delta.logRetentionDuration would look like in that case.
Storage is cheap, right?
Unified Batch & Streaming
Delta tables are both batch tables and streaming sources/sinks. I’ll refrain from joining that debate, but hey, flexibility is good.
Using Delta, you get all the benefits of streaming and batch— streaming ingest, batch backfill, interactive queries, etc. It’s a very flexible format, and the ability to have all of these features and support streaming functionality of Spark is what I would call:

DML
Delta supports merge, update, and delete operations— making things like change data capture (CDC), slowly changing dimensions (SCD), and streaming upserts possible. Merge/update/delete are powerful tools that enable foundational datastores.
One of the first posts I ever wrote was about creating an SCD Type-2 table using UPSERT in Delta. Admittedly, that was in 2021 and I had little idea what I was doing. Hopefully, someone has a better guide or much-improved process by now. 😂
SO let’s talk about the underlying technology that makes most of these possible.
📜 The Transaction Log
Here’s the part where I save you from reading a 15,000-word technical document! See, 4 readers can’t be wrong— we’re just delivering value here, nonstop.
So if Delta files are Parquet + the transaction log, we know the transaction log must be pretty special… otherwise, we’d just have Parquet files. While I do love Parquet files, I’m not sure they would warrant as much hype.

The transaction log works by breaking down transactions into atomic commits, the atomicity in ACID. So, whenever you perform an operation that modifies a table, Delta Lake breaks it down into one of the following discrete steps:
- Add a file
- Remove a file
- Update metadata
- Set transaction
- Change protocol
- Commit info
In that sense, it’s sort of like Git, but not really. There isn’t the ability to branch, rollback, merge, or do actual Git stuff. You just get the versioning. If you’re looking for a true “git for data lakes” consider Delta + lakeFS, which promises just that.
Some of you might be saying “That’s great, but how is Delta storing all of that transaction data? That could get pretty cumbersome!”
That’s a valid concern! Delta creates a _delta_log subdirectory within every Delta Lake table. As changes are made, each commit is recorded in a JSON file, starting with 0 and incrementing up.
Delta will automatically generate checkpoint files for good read performance on every 10th commit, e.g. 0000010.json. Checkpoint files save the entire state of the table at a point in time, in native Parquet.
Let’s take a look (in real-time)!
⏰ Demo time
I recommend opening this in full-screen to see the code! Here’s the full code from the demo, if you’d like to try it at home. 😀
The transaction log sees all 👀

🥋 UniForm
Up to this point, we’ve only discussed the fundamentals of Delta, but the team has been really innovating lately— at the Databricks Data+AI Summit a few weeks ago, Delta 3.0 was announced.
There are three headline features of the release, but we’ll focus on numero uno: Delta Universal Format (UniForm). With UniForm, ANY tool that can read Iceberg or Hudi… can also read Delta Lake.
With UniForm, customers can choose Delta with confidence, knowing that by choosing Delta, they’ll have broad support from any tool that supports lakehouse formats.
The new functionality is pretty impressive. Since all three formats are Parquet-based and solely differentiated by their metadata, UniForm provides the framework for translating this metadata. Have an Iceberg table? It’s now effectively a Delta table (with some limitations).
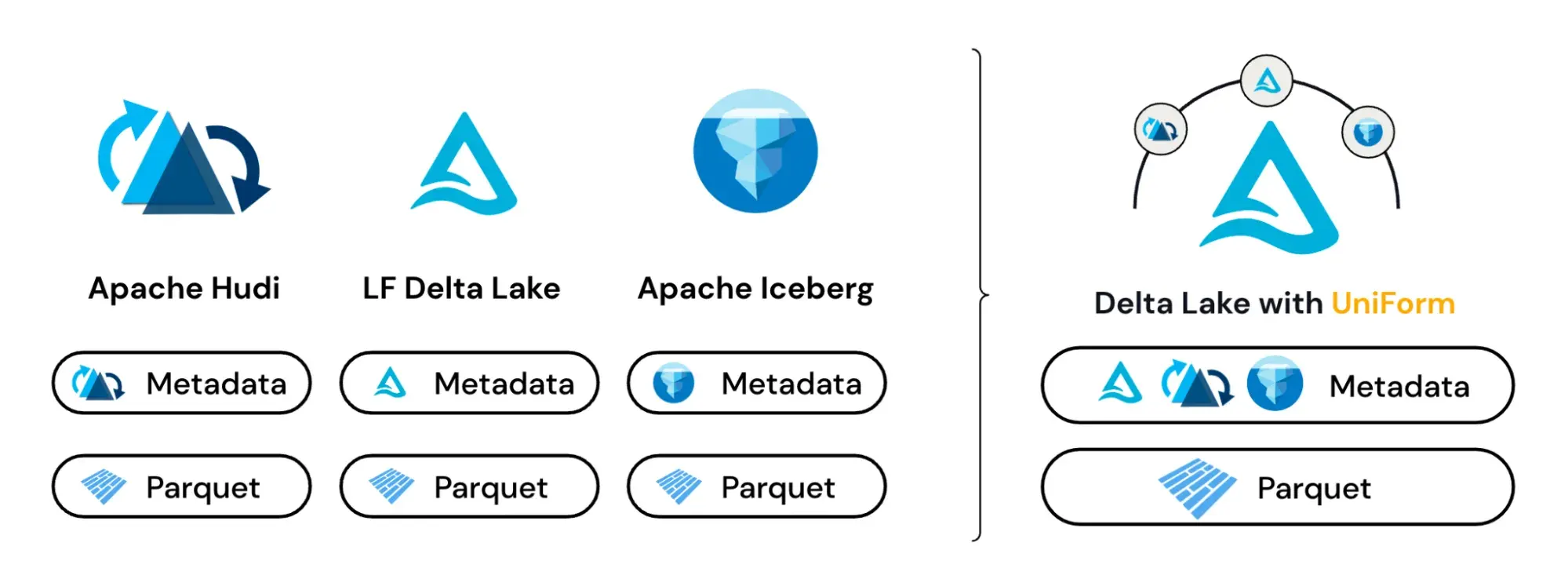
Perhaps more impressive is that UniForm improves read performance for Iceberg. So not only does UniForm consolidate formats and unify infrastructure— it can result in performance enhancements for non-native formats, too!
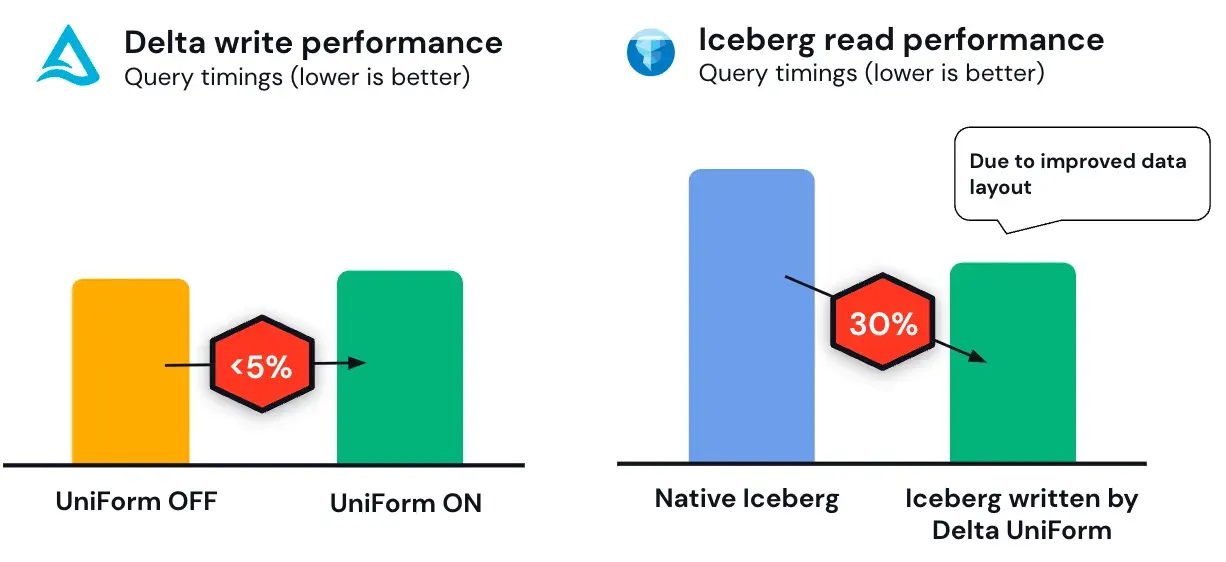
This is some 4D chess-type stuff from Databricks. It’s a way for them to say “Hey, we’re unifying the data space,” while continuing to build market share and keep their formats in production. It’s a clever one, for sure. We saw the same theme at the Data+AI Summit, where a major focus was on providing services that were universally accessible (marketplace, apps, etc).
This parallels Snowflake’s announcement of managed Iceberg Catalog support. My hunch is that Databricks saw the writing on the wall and wanted to avoid a situation where using Iceberg = using Snowflake.
WAIT! We don’t talk about things without explaining them first, so what’s a catalog? Let’s hear it straight from Snowflake:
A key benefit of open table formats, such as Apache Iceberg, is the ability to use multiple compute engines over a single copy of the data. What enables multiple, concurrent writers to run ACID transactions is a catalog. A catalog tracks tables and abstracts physical file paths in queries, making it easier to interact with tables. A catalog serves as an option to ensure all readers have the same view, and to make it cleaner to manage the underlying files.
That’s a great description! So the catalog “orchestrates” the transaction logging and functionality of individual Delta/Iceberg/Hudi tables across organizations with concurrent reads/writes.
If you thought, “Huh, I wonder if Databricks has a competing service,” you’d be 💯 percent correct. Unity Catalog is a much more complex topic, so we’ll save that discussion for another post, but you can read more here.
While I’m largely against the Databricks/Snowflake beef, it’s awesome to see competition producing something good for the community— interoperability is undoubtedly a win. Improving performance across formats benefits everyone. I applaud them on their decision and work— I think it’s insanely cool.
Conclusion
That’s pretty much it! Delta’s a great example of powerful technology: simple at its core, but insanely functional in practice. With Delta 3.0, the team continues to innovate and takes a major step towards the unification of lakehouse storage frameworks.
Yes, the term lakehouse is annoying and every presentation makes a joke about it, but it’s here to stay so I might as well use it. At the very least, we, as a data community, need to come up with better puns.
In a future post, we might dig into some more advanced features of Delta like Liquid Clustering (and ZORDER by relation), Unity Catalog, and Optimistic Concurrency Control.
If you have a topic you’d like to see here, drop me a note!