✏️ This post is adapted from a contribution I made to dataengineering.wiki. I highly recommend you check out their site & community! 💜

ToC
Open ToC
🏃♂️ Going for Gold
In the theme of my last article, we’re continuing with Databricks-inspired buzzwords. I like this one because it lets me make liberal use of running emojis. 🤷♂️
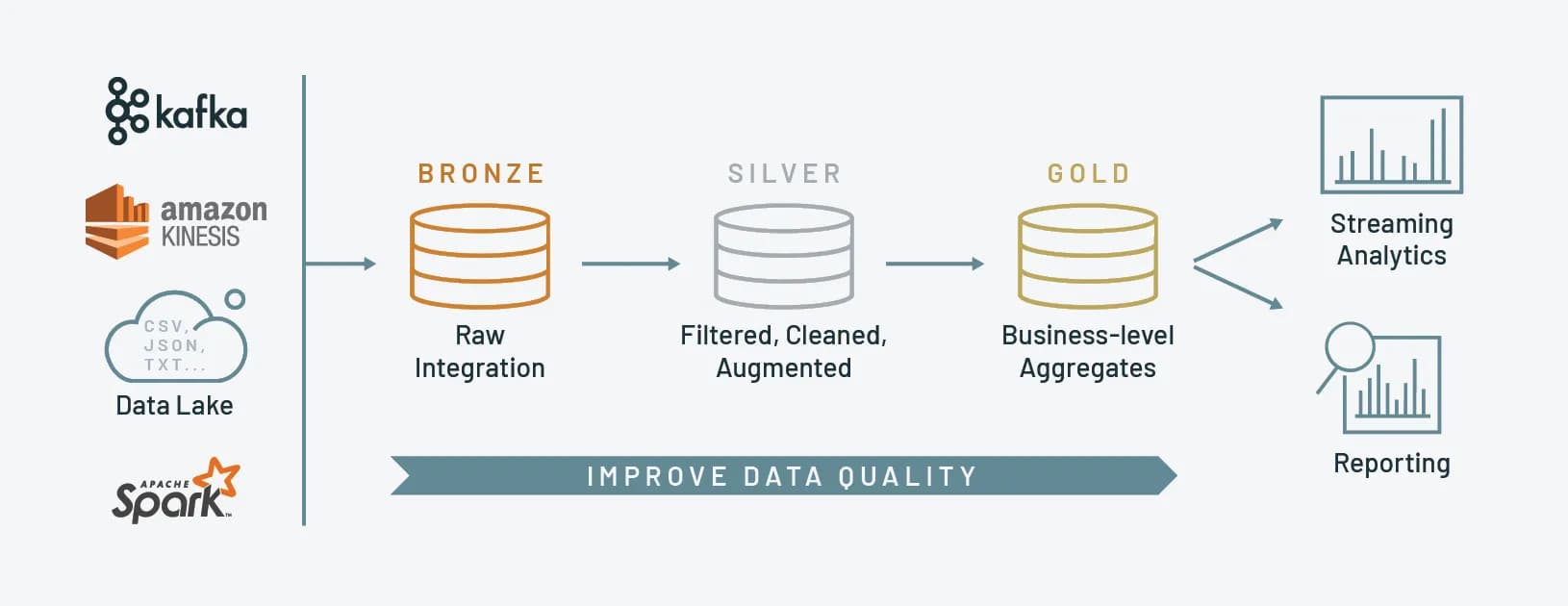
A medallion architecture is a data design pattern used to logically organize data in a lakehouse; to incrementally improve the quality of data as it flows through data quality “layers.”
This architecture consists of three distinct layers – bronze (raw), silver (validated), and gold (enriched) – each representing progressively higher levels of quality. Medallion architectures are sometimes referred to as “multi-hop” architectures.
Medallion architectures came about as lakehouse and lakehouse storage formats (e.g. Delta, Iceberg, Hudi) became more widely adopted. That is when Spark and PySpark started to overtake older frameworks for distributed processing.
If you have a background in data warehousing— this probably sounds familiar! dbt currently recommends a
staging ➡️ intermediate ➡️ marts
process for cleaning data. The convention isn’t so important, I’ve also seen:
raw ➡️ stg ➡️ curated,
clean ➡️ views,
plus a bunch of other terms like protected and reporting, but the idea is the same: create simple data “layers” that represent stages in the transformation process and delineate data cleanliness.
🚉 Medallion Stages
🥉 Bronze
The bronze stage serves as the initial point for data ingestion and storage. Data is saved without processing or transformation. This might be saving logs from an application to a distributed file system or streaming events from Kafka.
🥈 Silver
The silver layer is where tables are cleaned, filtered, or transformed into a more usable format. Note that the transformations here should be light modifications, not aggregations or enrichments. From our first example, those logs might be parsed slightly to extract useful information— like unnesting structs or eliminating abbreviations. Our events might be standardized to coalesce naming conventions or split a single stream into multiple tables.
🥇 Gold
Finally, in the gold stage, data is refined to meet specific business and analytics requirements. This might mean aggregating data to a certain grain, like daily/hourly, or enriching data with information from external sources. After the gold stage, data should be ready for consumption by downstream teams, like analytics, data science, or ML ops.
🧐 Why Layers?
The layer concept is not new: you might be familiar with it if you’ve worked in data warehousing.
It’s funny in a sense: though we’ve seen an explosion of new data tech, many concepts have remained the same. I remember a video that an (excellent) analytics manager showed me in 2018. If you’re expecting irrelevant, out-of-date concepts, brace yourself:
It’s a bit on the longer side, but if you shuffle through, you’ll find Tom O’Neill, former Co-Founder of Periscope Data (🪦 RIP), discussing fundamental data warehousing ideas, many of which are still extremely relevant.
Now, don’t get me wrong— I’m not saying medallion architecture = data warehousing or anything of the sort, really.
I’m simply emphasizing that medallion architecture is just a common pattern in data storage that’s been around for a while. Maybe even before dbt recommended it… It has different uses in a data lake, but for the analysts out there, you can think of this as a data engineer’s version of your “protective views” 😉
This one just has a fancy name. See, there’s a method behind the madness.

🤓 Why Medallion?
Medallion is similar to our data warehouse analogy with some key differences. So, what does Medallion do well? What doesn’t it do so well? You’ve already read this far— might as well find out!
🔄 Upstream changes
With a layered architecture, we can eliminate most of the headaches from upstream schema changes. What usually happens when an upstream source changes?

Clever engineers and analysts have taken note! With multiple layers of storage, we have a single breakpoint to remedy changes. Column name changed from createdAt to created_at? No big deal! We’ll just rename createdAt ➡️ created_at in our silver layer: a simple and incredibly effective solution. Thought this would be further evidence that any data using camel case is extremely sus. 🤨
Medallion architecture can be used to protect against schema changes from external sources, which your team has no control over, and internal sources, which ideally have data contracts, but likely don’t.
🚤 Lakehouse benefits
Additional benefits are obtained when using a lakehouse storage format, though it’s not a prerequisite. I’ve discussed Delta Lake and lakehouse tech before, but the gist is these formats record changes in a “transaction log” and thus have the ability to “time travel” for some retention period.
Separate layers + ACID guarantees + time travel makes versioned and incrementally stored data a reality— a boon for disaster recovery, audits, and overall understanding of a data pipeline.
Just think about that. For the duration of your retention policy, you can replay your entire data lake/warehouse and rebuild all downstream sources. 🤯
Simplicity
The incremental layers of Medallion beget simplicity and organization. Rather than making every change at once, staged tables bring clarity to data processing and introduce conventions that your team can follow.
As an engineer, there’s a much lower cognitive load to making a change on a tiered processing system than an ad-hoc one. Medallion systems will be easier to maintain and onboard new users.
🙈 What Medallion Isn’t
We’ve talked about what Medallion is and who it’s for, but here are some downsides and problems Medallion doesn’t solve.
- Medallion doesn’t replace dimensional modeling: schemas and tables within each layer must still be modeled. Medallion architecture provides a framework for data cleaning and storage. You can’t throw away your copy of The Data Warehouse Toolkit and adopt a Medallion Architecture.
- Medallion uses large amounts of storage: though, as many have proclaimed, “storage is cheap,” Medallion architecture effectively triples the amount of storage in a data lake. For that reason, it might not be practical for data teams with intensive storage demands. Hey, it’s 2023 and interest rates are nearing 6%. We can’t be dropping stacks on cloud services anymore. 💸
- Medallion requires additional downstream processing: there still needs to be a place for analysts/analytics engineers to build business-oriented transformations that power BI. Some teams might prefer those processes remain separate, rather than having analysts develop in the gold layer. As such, a medallion architecture is not a drop-in replacement for existing data transformation solutions. You likely still need a warehouse. Though I have heard of analytics teams migrating to a pure data lake, I wouldn’t recommend that.
- Medallion implies a lakehouse architecture: if a lakehouse is impractical for your team, this architecture might not make sense. Medallion architectures can be used effectively in hybrid data lake/warehouse implementations, as I alluded to above, but if your team isn’t ready for a data lake/lakehouse solution, there are always staging layers in a database. 😄
📽️ Recap
A medallion architecture is a data engineer’s version of warehouse storage layers. It pairs quite nicely with lakehouse formats— like a fine wine 🍷. It can help to keep your data tidy and organized. It even comes with some great disaster recovery benefits.
No, it’s not going to replace your data warehouse and no, you can’t forget everything you know about dimensional modelling. You can however have greater confidence in your data engineering pipelines and use more Forest Gump gifs in your documentation.
